Data description and codebook#
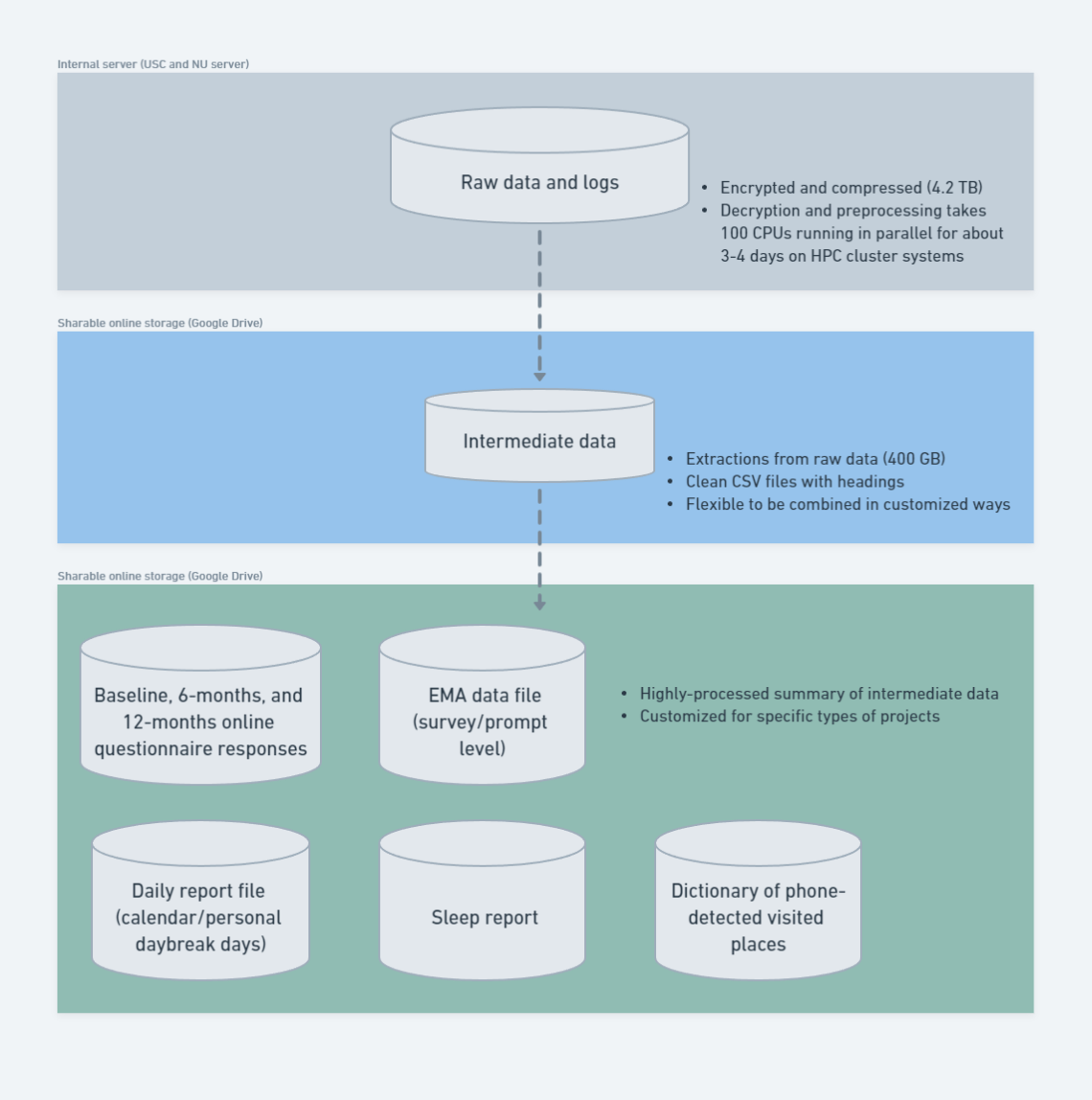
The rich data collected in TIME study are processed and stored at different levels to serve different purposes and researchers with various programming backgrounds. From raw date collections to more processed datasets, they include:
Raw data and logs that are in original form that preserves maximal information;
Intermediate data that are processed to extracts useful information from the raw data and have a cleaner format at the same time;
Processed datasets that include fully cleaned data with summary variables included and may combine cleaned data from different raw and intermediate datasets, being in a refined CSV format that can be directly imported into statistical softwares.
Details about these datasets can be found in their codebooks.
Data Processing Pipeline
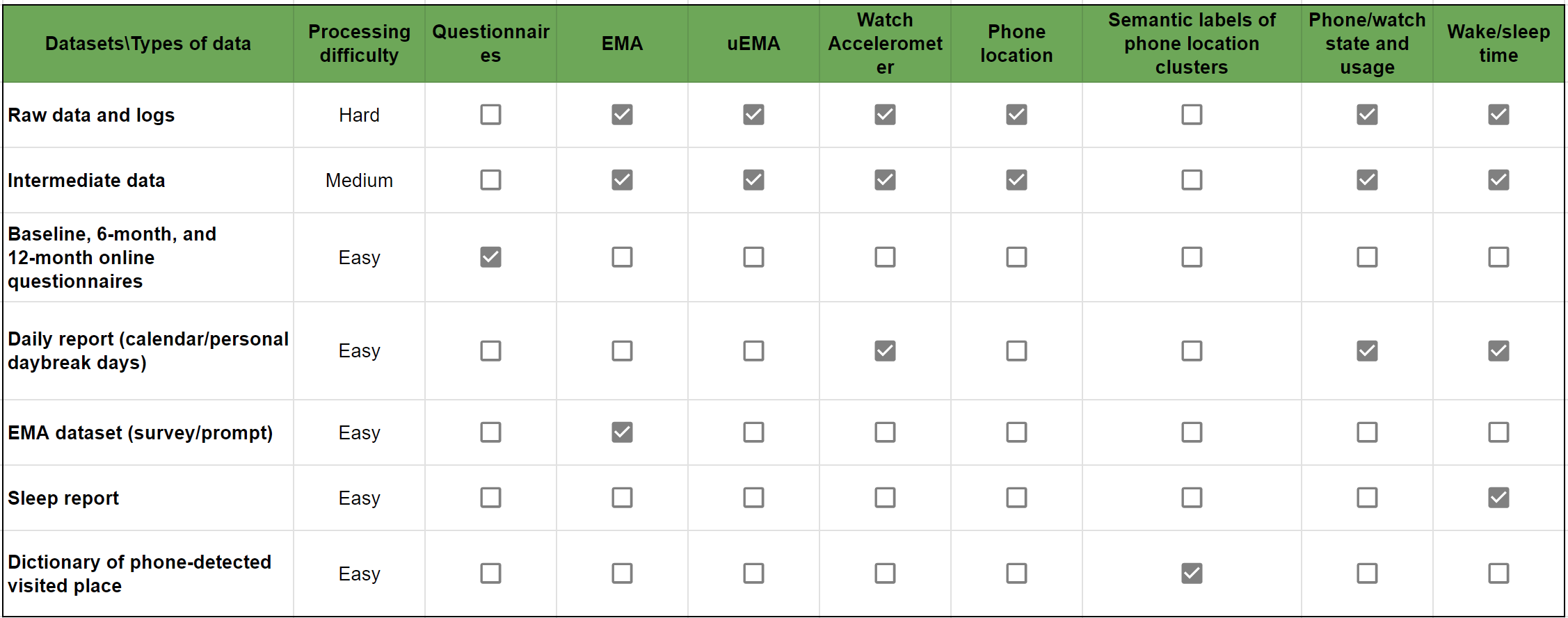
Types of Data in Each Dataset
Raw data and logs (recommended for experienced programmer)
Description: all data and logs are encrypted and stored in their raw format after being directly pulled from devices. It contains all kinds of logs including those used for debugging purposes. Most files have data format issues, such as missing headers, duplicate rows, logging errors, etc.
Codebook: Link
Intermediate data (recommended for experienced programmer)
Description: data and logs are extracted from the raw data and logs and cleaned to be free of format issues as in raw data format. Every file is stored in csv format with a header. Researchers with strong programming skills can start analysis with data at this stage. See more details about data processing of first, second, and third passes on discovery cluster here.
Location: discovery cluster
Codebook: Link
Processed Data (recommended for researchers without extensive programming experience)
Baseline, 6-month, and 12-month online questionnaires: sociodemographic variables, mental health characteristics, health status, health behaviors, and other covariates are assessed at three time points (baseline, 6 months, 12 months) using online electronic questionnaires completed remotely on a computer, tablet, or smartphone. The surveys were administered through USC’s REDCap system. Codebook
Daily report (calendar days): a single csv file that contains an aggregated summary of statistics for each participant and calendar day. Files are at day level for each participant, and stored in /participantID/YYYY-MM-DD/. This file was originally used for compliance check during the study. Codebook Example file
Daily report (personal daybreak days): a single csv file that contains an aggregated summary of statistics for each participant and personal daybreak day. The format is similar to the calendar day daily report except the day is defined based on an individual’s wake and sleep time. Codebook Example file
EMA survey dataset: a single csv file of all prompted EMA surveys and responses, including EMA Measurement Burst Data, EMA Daily Data, and EMA Weekly (i.e., Sunday) Data (with the COVID questionnaire). R code and instruction Codebook
EMA prompt dataset: a single csv file of all EMA prompts and reprompts, including sensor data aggregates that are 30/60/90/120/150/180 minutes before and after the prompt time. No survey responses are included. Codebook Example file
Sleep report: a single csv file of self-reported and watch-detected sleep and wake time of all days in study. The self-reported sleep and wake time include prospective (i.e., estimated time before sleep) and retrospective (i.e., recalled time after sleep) sleep and wake time. Other sleep metrics are included as well. Codebook Example file
Dictionary of phone-detected visited places: a single csv file of meta information about visited places detected from each participant’s smartphones throughout the study. The meta information for each place (location cluster) include semantic labels (from CS-EMA, exit-interview, and OpenStreetMap) and visiting information by the participant (polygon area, time spent, number of visits, etc.). Codebook Example file